
之前就有网友在博客里留言,觉得webmagic的实现比较有意思,想要借此研究一下爬虫。最近终于集中精力,花了三天时间,终于写完了这篇文章。之前垂直爬虫写了一年多,webmagic框架写了一个多月,这方面倒是有一些心得,希望对读者有帮助。
webmagic的目标
一般来说,一个爬虫包括几个部分:
页面下载
页面下载是一个爬虫的基础。下载页面之后才能进行其他后续操作。
链接提取
一般爬虫都会有一些初始的种子URL,但是这些URL对于爬虫是远远不够的。爬虫在爬页面的时候,需要不断发现新的链接。
URL管理
最基础的URL管理,就是对已经爬过的URL和没有爬的URL做区分,防止重复爬取。
内容分析和持久化
一般来说,我们最终需要的都不是原始的HTML页面。我们需要对爬到的页面进行分析,转化成结构化的数据,并存储下来。
不同的爬虫,对这几部分的要求是不一样的。
对于通用型的爬虫,例如搜索引擎蜘蛛,需要指对互联网大部分网页无差别进行抓取。这时候难点就在于页面下载和链接管理上—如果要高效的抓取更多页面,就必须进行更快的下载;同时随着链接数量的增多,需要考虑如果对大规模的链接进行去重和调度,就成了一个很大的问题。一般这些问题都会在大公司有专门的团队去解决,比如这里有一篇来自淘宝的快速构建实时抓取集群。
而垂直类型的爬虫要解决的问题则不一样,比如想要爬取一些网站的新闻、博客信息,一般抓取数量要求不是很大,难点则在于如何高效的定制一个爬虫,可以精确的抽取出网页的内容,并保存成结构化的数据。这方面需求很多,webmagic就是为了解决这个目的而开发的。
使用Java语言开发爬虫是比较复杂的。虽然Java有很强大的页面下载、HTML分析工具,但是每个都有不小的学习成本,而且这些工具本身都不是专门为爬虫而生,使用起来也没有那么顺手。我曾经有一年的时间都在开发爬虫,重复的开发让人头痛。Java还有一个比较成熟的框架crawler4j,但是它是为通用爬虫而设计的,扩展性差一些,满足不了我的业务需要。我也有过自己开发框架的念头,但是终归觉得抽象的不是很好。直到发现python的爬虫框架scrapy,它将爬虫的生命周期拆分的非常清晰,我参照它进行了模块划分,并用Java的方式去实现了它,于是就有了webmagic。
代码已经托管到github,地址是https://github.com/code4craft/webmagic,Javadoc:http://code4craft.github.io/webmagic/docs/
webmagic的实现还参考了另一个Java爬虫SpiderMan。SpiderMan是一个全栈式的Java爬虫,它的设计思想跟webmagic稍有不同,它希望将Java语言的实现隔离,仅仅让用户通过配置就完成一个垂直爬虫。理论上,SpiderMan功能更强大,很多功能已经内置,而webmagic则比较灵活,适合熟悉Java语法的开发者,可以比较非常方便的进行扩展和二次开发。
webmagic的模块划分
webmagic目前的核心代码都在webmagic-core中,webmagic-samples里有一些定制爬虫的例子,可以作为参考。而webmagic-plugin目前还不完善,后期准备加入一些常用的功能。下面主要介绍webmagic-core的内容。
前面说到,webmagic参考了scrapy的模块划分,分为Spider(整个爬虫的调度框架)、Downloader(页面下载)、PageProcessor(链接提取和页面分析)、Scheduler(URL管理)、Pipeline(离线分析和持久化)几部分。只不过scrapy通过middleware实现扩展,而webmagic则通过定义这几个接口,并将其不同的实现注入主框架类Spider来实现扩展。
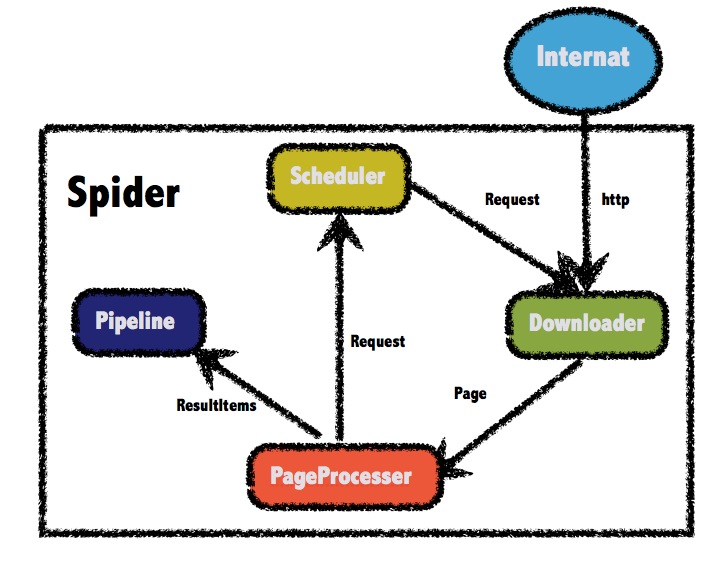
Spider类-核心调度
Spider是爬虫的入口类,Spider的接口调用采用了链式的API设计,其他功能全部通过接口注入Spider实现,下面是启动一个比较复杂的Spider的例子。
1 2 3 4 | |
Spider的核心处理流程非常简单,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Downloader-页面下载
页面下载是一切爬虫的开始。
大部分爬虫都是通过模拟http请求,接收并分析响应来完成。这方面,JDK自带的HttpURLConnection可以满足最简单的需要,而Apache HttpClient(4.0后整合到HttpCompenent项目中)则是开发复杂爬虫的不二之选。它支持自定义HTTP头(对于爬虫比较有用的就是User-agent、cookie等)、自动redirect、连接复用、cookie保留、设置代理等诸多强大的功能。
webmagic使用了HttpClient 4.2,并封装到了HttpClientDownloader。学习HttpClient的使用对于构建高性能爬虫是非常有帮助的,官方的Tutorial就是很好的学习资料。目前webmagic对HttpClient的使用仍在初步阶段,不过对于一般抓取任务,已经够用了。
下面是一个使用HttpClient最简单的例子:
1 2 3 4 | |
对于一些Javascript动态加载的网页,仅仅使用http模拟下载工具,并不能取到页面的内容。这方面的思路有两种:一种是抽丝剥茧,分析js的逻辑,再用爬虫去重现它(比如在网页中提取关键数据,再用这些数据去构造Ajax请求,最后直接从响应体获取想要的数据); 另一种就是:内置一个浏览器,直接获取最后加载完的页面。这方面,js可以使用PhantomJS,它内部集成了webkit。而Java可以使用Selenium,这是一个非常强大的浏览器模拟工具。考虑以后将它整理成一个独立的Downloader,集成到webmagic中去。
一般没有必要去扩展Downloader。
PageProcessor-页面分析及链接抽取
这里说的页面分析主要指HTML页面的分析。页面分析可以说是垂直爬虫最复杂的一部分,在webmagic里,PageProcessor是定制爬虫的核心。通过编写一个实现PageProcessor接口的类,就可以定制一个自己的爬虫。
页面抽取最基本的方式是使用正则表达式。正则表达式好处是非常通用,解析文本的功能也很强大。但是正则表达式最大的问题是,不能真正对HTML进行语法级别的解析,没有办法处理关系到HTML结构的情况(例如处理标签嵌套)。例如,我想要抽取一个<div>里的内容,可以这样写:”<div>(.*?)</div>“。但是如果这个div内部还包含几个子div,这个时候使用正则表达式就会将子div的”</div>“作为终止符截取。为了解决这个问题,我们就需要进行HTML的分析。
HTML分析是一个比较复杂的工作,Java世界主要有几款比较方便的分析工具:
Jsoup
Jsoup是一个集强大和便利于一体的HTML解析工具。它方便的地方是,可以用于支持用jquery中css selector的方式选取元素,这对于熟悉js的开发者来说基本没有学习成本。
1 2 3 | |
Jsoup还支持白名单过滤机制,对于网站防止XSS攻击也是很好的。
HtmlParser
HtmlParser的功能比较完备,也挺灵活,但谈不上方便。这个项目很久没有维护了,最新版本是2.1。HtmlParser的核心元素是Node,对应一个HTML标签,支持getChildren()等树状遍历方式。HtmlParser另外一个核心元素是NodeFilter,通过实现NodeFilter接口,可以对页面元素进行筛选。这里有一篇HtmlParser的使用文章:使用 HttpClient 和 HtmlParser 实现简易爬虫。
Apache tika
tika是专为抽取而生的工具,还支持PDF、Zip甚至是Java Class。使用tika分析HTML,需要自己定义一个抽取内容的Handler并继承org.xml.sax.helpers.DefaultHandler,解析方式就是xml标准的方式。crawler4j中就使用了tika作为解析工具。SAX这种流式的解析方式对于分析大文件很有用,我个人倒是认为对于解析html意义不是很大。
1 2 3 4 | |
HtmlCleaner与XPath
HtmlCleaner最大的优点是:支持XPath的方式选取元素。XPath是一门在XML中查找信息的语言,也可以用于抽取HTML元素。XPath与CSS Selector大部分功能都是重合的,但是CSS Selector专门针对HTML,写法更简洁,而XPath则是通用的标准,可以精确到属性值。XPath有一定的学习成本,但是对经常需要编写爬虫的人来说,这点投入绝对是值得的。
学习XPath可以参考w3school的XPath 教程。下面是使用HtmlCleaner和xpath进行抽取的一段代码:
1 2 3 | |
几个工具的对比
在这里评价这些工具的主要标准是“方便”。就拿抽取页面所有链接这一基本任务来说,几种代码分别如下:
XPath:
1
| |
CSS Selector:
1 2 | |
HtmlParser:
1 2 3 4 5 6 7 8 9 10 | |
XPath是最简单的,可以精确选取到href属性值;而CSS Selector则次之,可以选取到HTML标签,属性值需要调用函数去获取;而HtmlParser和SAX则需要手动写程序去处理标签了,比较麻烦。
webmagic的Selector
Selector是webmagic为了简化页面抽取开发的独立模块,是整个项目中我最得意的部分。这里整合了CSS Selector、XPath和正则表达式,并可以进行链式的抽取,很容易就实现强大的功能。即使你使用自己开发的爬虫工具,webmagic的Selector仍然值得一试。
例如,我已经下载了一个页面,现在要抽取某个区域的所有包含”blog”的链接,我可以这样写:
1 2 3 4 5 6 7 | |
另外,webmagic的抓取链接需要显示的调用Page.addTargetRequests()去添加,这也是为了灵活性考虑的(很多时候,下一步的URL不是单纯的页面href链接,可能会根据页面模块进行抽取,甚至可能是自己拼凑出来的)。
补充一个有意思的话题,就是对于页面正文的自动抽取。相信用过Evernote Clearly都会对其自动抽取正文的技术印象深刻。这个技术又叫Readability,webmagic对readability有一个粗略的实现SmartContentSelector,用的是P标签密度计算的方法,在测试oschina博客时有不错的效果。
Scheduler-URL管理
URL管理的问题可大可小。对于小规模的抓取,URL管理是很简单的。我们只需要将待抓取URL和未抓取URL分开保存,并进行去重即可。使用JDK内置的集合类型Set、List或者Queue都可以满足需要。如果我们要进行多线程抓取,则可以选择线程安全的容器,例如LinkedBlockingQueue以及ConcurrentHashMap。
因为小规模的URL管理非常简单,很多框架都并不将其抽象为一个模块,而是直接融入到代码中。但是实际上,抽象出Scheduler模块,会使得框架的解耦程度上升一个档次,并非常容易进行横向扩展,这也是我从scrapy中学到的。
在webmagic的设计中,除了Scheduler模块,其他的处理-从下载、解析到持久化,每个任务都是互相独立的,因此可以通过多个Spider共用一个Scheduler来进行扩展。排除去重的因素,URL管理天生就是一个队列,我们可以很方便的用分布式的队列工具去扩展它,也可以基于mysql、redis或者mongodb这样的存储工具来构造一个队列,这样构建一个多线程乃至分布式的爬虫就轻而易举了。
URL去重也是一个比较复杂的问题。如果数据量较少,则使用hash的方式就能很好解决。数据量较大的情况下,可以使用Bloom Filter或者更复杂的方式。
webmagic目前有两个Scheduler的实现,QueueScheduler是一个简单的内存队列,速度较快,并且是线程安全的,FileCacheQueueScheduler则是一个文件队列,它可以用于耗时较长的下载任务,在任务中途停止后,下次执行仍然从中止的URL开始继续爬取。
Pipeline-离线处理和持久化
Pipeline其实也是容易被忽略的一部分。大家都知道持久化的重要性,但是很多框架都选择直接在页面抽取的时候将持久化一起完成,例如crawer4j。但是Pipeline真正的好处是,将页面的在线分析和离线处理拆分开来,可以在一些线程里进行下载,另一些线程里进行处理和持久化。
你可以扩展Pipeline来实现抽取结果的持久化,将其保存到你想要保存的地方-本地文件、数据库、mongodb等等。Pipeline的处理目前还是在线的,但是修改为离线的也并不困难。
webmagic目前只支持控制台输出和文件持久化,但是持久化到数据库也是很容易的。
结语
webmagic确实是一个山寨的框架,本身也没有太多创新的东西,但是确实对Java爬虫的实现有了一些简化。在强大便利的功能和较高的灵活性中间,webmagic选择了后者,目标就是要打造一个熟练的Java开发者也用的比较顺手的工具,并且可以集成到自己的业务系统中,这一点我自己开发了不少这样的业务,对其灵活性还是比较有信心的。webmagic目前的代码实现还比较简单(不到2000行),如果有兴趣的阅读代码可能也会有一些收获,也非常欢迎建议和指正。