本文是一次线上OOM故障排查的经过,内容比较基础但是真实,主要是记录一下,没有OOM排查经验的同学也可以参考。
现象
我们之前有一个计算作业。最近经常出现不稳定,无法正常响应的情况。具体表现是:各种连接超时,从mysql、mongodb和zookeeper到netty,能超时的都超时过了。其他看不到太多有效的异常。
所以我们首先怀疑的是网络问题,打电话跟运维确认,运维说网络问题的可能性几乎为0,因为我们的机器是虚机,宿主机上的其他设备都运转正常。程序问题的可能性更大。继续从应用日志和tomcat的catalina.out中查找日志,发现有一些OutOfMemoryError异常。实际上,出现这个异常就代表内存不够了。
我们使用cat(公司的Java监控平台,已开源https://github.com/dianping/cat)查看堆使用的情况,看到如下的东西:

Memory Free已经接近了0,同时产生了大量的fullgc。
回到之前的连接timeout,我们知道,Java的连接timeout,除了网络传输的时间,也包括了Java程序处理的时间,所以OOM导致timeout也不奇怪了。
工具和排查
之前JVM分析做的很少,在同事的帮助下,结合一点资料,完成了基本的分析。
首先可用的是
jmap -histo PID
这个命令会将内存中最终保存的对象列出来。
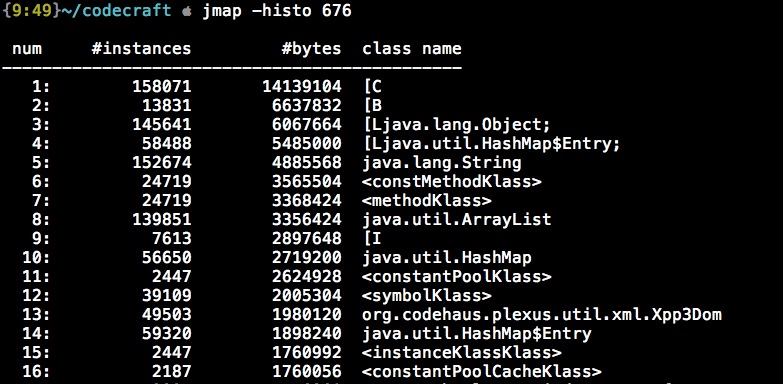
其中”[“表示数组,例如”[B”是byte[],具体可以看Class.getName()的Javadoc。
但是这个只能粗略定位原因,如果要仔细分析,需要知道是哪些个对象持有了它,这个时候,就需要dump内存下来,再离线分析了。
dump内存的命令是:
jmap -dump:format=b,file=/home/admin/dump.bin PID
此操作异常耗时,我跟运维在假死的机器上尝试了几次,竟然把tomcat进程干掉了,使用时还是小心为妙…
我这里使用VisualVM进行分析,大致效果如下:

这里选择“计算保留大小”。这个保留大小是递归计算实例之间的依赖,得到的总大小。因为去掉了循环依赖,所以并不完全准确,但是用于排查够了。
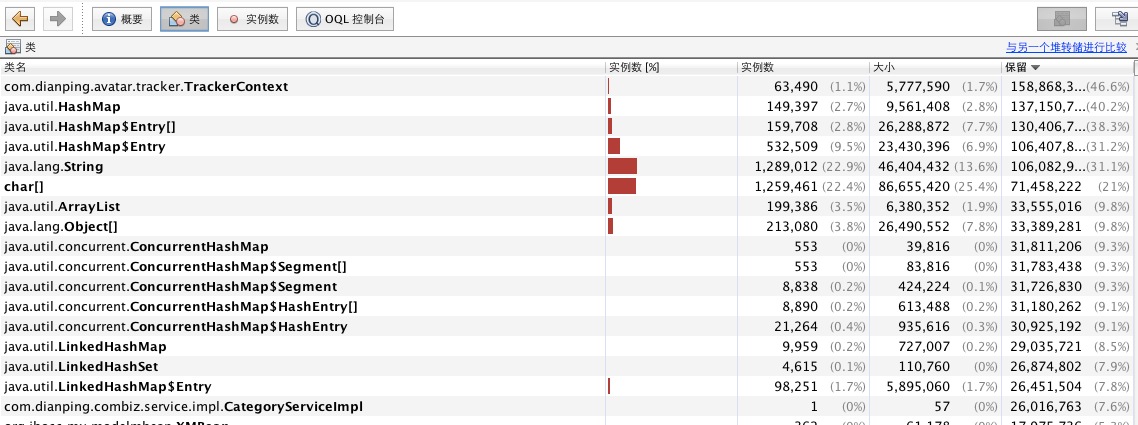
最后排查出的结果,是公司的RPC中间件使用了ThreadLocal来保存一个context,但是最后却没有释放。按照架构组的说明,升级了版本,问题解决!